
最近よく Snowflake, Databricks 社のサービスを目にするようになり、私の所属している会社でも(部署は違いますが)Snowflake の導入を行っているようです。その中で "Data Lakehouse" という単語を目にしたので、どういう概念なのかを調べました。
実際に動かしたりしていないので半分自分のための備忘録として書いているのですが、明らかに誤った説明があればご指摘ください。
Databricks 社からの論文
このレイクハウスという考え方は GCP, AWS などのクラウドベンダーでも紹介されていて、徐々に広まりつつある考え方のように見えます。Google Cloud の data lakehouse の解説記事に、Databricks の方が筆頭著者の論文が紹介されていました:
http://cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
この論文は CIDR 2021 にて発表されており、発表動画もありました:
要約を引用します:
This paper argues that the data warehouse architecture as we know it today will wither in the coming years and be replaced by a new architectural pattern, the Lakehouse, which will (i) be based on open direct-access data formats, such as Apache Parquet, (ii) have firstclass support for machine learning and data science, and (iii) offer state-of-the-art performance.
Lakehouses can help address several major challenges with data warehouses, including data staleness, reliability, total cost of ownership, data lock-in, and limited use-case support. We discuss how the industry is already moving toward Lakehouses and how this shift may affect work in data management.
We also report results from a Lakehouse system using Parquet that is competitive with popular cloud data warehouses on TPC-DS.
データウェアハウスは新しいアーキテクチャパターン、レイクハウスに置き換えられるだろうという強い主張があります。既存のデータウェアハウスには以下のような問題があると主張しています:
- データレイク・データウェアハウス間でデータ品質を保つことが難しい(微妙な差異が生まれたり、ETL処理においてバグなどが生じる可能性がある)
- データウェアハウスに届くまでに時間がかかる(データが古くなる)
- データウェアハウスは機械学習へのサポートを提供していない。データ抽出にはさらなる ETL ステップが必要となる
- データレイク・データウェアハウスの両方にストレージコストが生じる
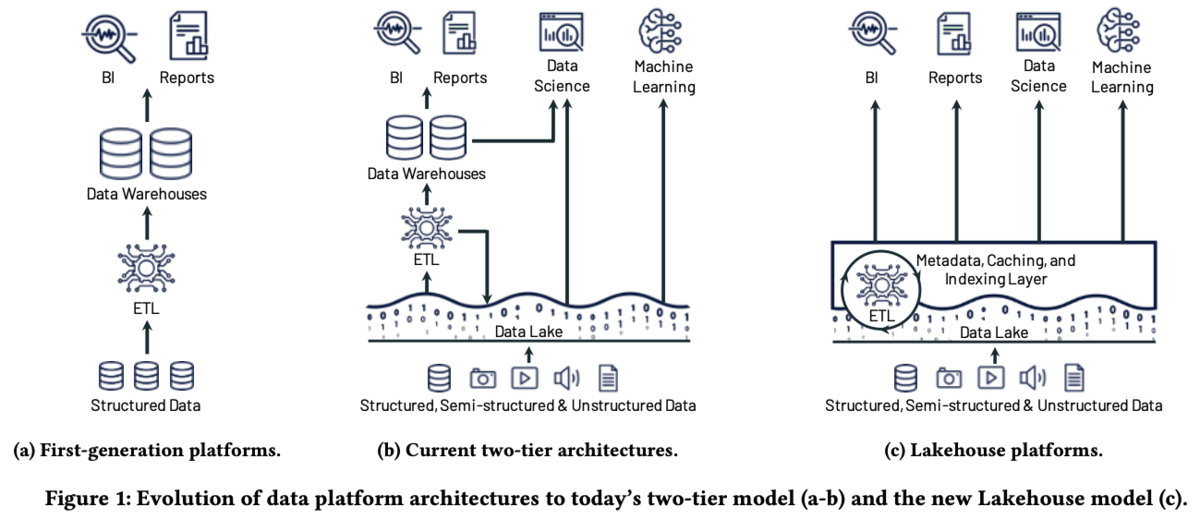
この問題を解決するために、データレイク自体にデータマネジメントの機能を持たせたり、機械学習・データサイエンスのサポートをしたり、データレイク自体にSQLを発行できるようにするというのが論文の趣旨です。下図は論文からもってきたものですが、(b) がデータレイク、データウェアハウスが分離された分かりやすいアーキテクチャですが、(c)(論文が主張する新しいアーキテクチャ) ではデータレイクが主役となっています。
疑問: Snowflake との違いは?
Snowflake も最近よく目にするようになり、どちらも似たような機能をもっているように見えたので、比較記事を読みました:
この2社のサービスは徐々に近づいてきているということですが、Snowflake はデータウェアハウス、Databricks は ETL 処理基盤として登場したとのこと。大きな違いは2つあり、1つ目は保存・処理できるデータ種別。Databricks の Delta Lake は非構造データ・半構造化データ・構造化データを扱えますが、Snowflake は構造化・半構造化データを対象にしているとのこと。しかし非構造化データについてもサポートを拡張し始めているようです。
2つ目はクエリパフォーマンス。これは当然といえば当然ですが、構造化・非構造化データを対象としている Snowflake, BigQuery, Redshift(そして Firebolt)に軍配が上がります。しかし論文にも書かれているように Databricks の Delta Engine には様々な工夫が凝らされており、Delta Lake に対するパフォーマンスを向上させています。
記事中にもありますが、どちらが良いかはケースバイケースですし、Snowflake, Databricks どちらも使っているパターンも多いとのこと。データウェアハウスを中心にクエリパフォーマンスを重要視するなら Snowflake, データレイクを中心に機械学習・データサイエンスのサポートをしたいなら Databricks…といった感じなんでしょうか。
疑問: データモデリングはどこに行ったのか?
このブログで以前データモデリングの話をしました。昨今はデータモデリングが必要な文脈が変わってきて、データモデルをもとにきちんと整備されたデータをデータウェアハウスに格納するのではなく、データレイクに格納したデータの関係性を理解するためにデータモデリングが必要になってきているのではないか、ということでした。
レイクハウスでも Metadata レイヤーが存在する通り、データマネジメントの機能は需要だと考えており、データ品質やデータガバナンスをこのレイヤーで担保することが論文では書かれていますが、データモデリングについては述べられていません。運用上の課題に近いので論文中で議論される必要はないのですが、データレイクに存在するデータを扱いやすくしたようなレイクハウスアーキテクチャにおいて、データ同士の関係性がどのように表現されるのかは気になります。