この一連の流れは 1:N の情報伝達手段であるマスメディアまで発展し、インターネットの登場によって成熟しきったと考えられるようです。そしてインターネットの利用が深まるにつれ、個人が発信する新しい時代(多対多、N:M)に突入していったというんですね。「文字」というテーマでここまで話が広がるのかと驚きます。
それからテレビを買って、少し地上波を見た後は Amazon Prime Video でひたすらドラマと映画を見ました。実家では能動的にテレビを見なかったので映画は何も分からなくて、そういえば父親は寅さん見てたなとか、昔スターウォーズ勧められたけど見なかったな、という感じで有名どころばかりですが楽しかったです。英語字幕で見るとリスニングの勉強にも多少なっていたので罪悪感がなくてよかったですし、おかげでその後受けた TOEIC のリスニングは大幅に点数が伸びて驚きました。
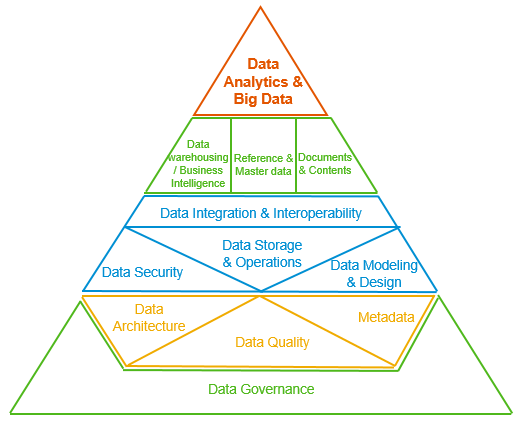
"Data Management at Scale" ではデータガバナンスについて、スタートアップや小さい企業では必要にならないと書かれています。これは小さい組織ではデータを管理するのは数人のみで、データも種類も比較的少ないからです。さらにデータに関する質問があれば、周りの人に聞けばすぐに解決できる状態だ、とも書かれています。
私の場合は A 2 or 3個/8個, B 7個/8個 でB(内向型)に寄っているようです。考えながら話すとか、人と話すとそれが楽しいものでも疲れる(外向型の場合は人と話すことがエネルギーの充電になるとのこと)、1日に予定は詰め込みたくない等々、当てはまる性質が多いです。ふいに電源が切れたように思考や口が回らなくなったりする、といったことも書いてあって、驚きました。実はよくあるんです。慣れない環境だったり、一緒にいることがストレスな人と長時間いると急に電源が切れたりして、そういう時は静かな場所で充電しないと次の活動ができません。

")